实现一个简单的Query
标签(空格分隔): JS JQ
前段时间写了一个简单的JQuery$函数,当然是在不使用querySelector的前提下。感觉自己对正则表达式书写,还有dom节点的遍历有了基础的认识。废话不多说,先说一下实现的功能:
// 可以通过id获取DOM对象,通过#标示,例如
$(“#adom”); // 返回id为adom的DOM对象
// 可以通过tagName获取DOM对象,例如
$(“a”); // 返回第一个对象
// 可以通过样式名称获取DOM对象,例如
$(“.classa”); // 返回样式定义包含classa的对象
// 可以通过attribute匹配获取DOM对象,例如
$(“[data-log]”); // 返回包含属性data-log的对象
$(“[data-time=2015]”); // 返回第一个包含属性data-time且值为2015的对象
// 可以通过简单的组合提高查询便利性,例如
$(“#adom .classa”); // 返回id为adom的DOM所包含的所有子节点中,第一个样式定义包含classa的对象
因为有复杂的组合查询,所以解决思路是确定要查询的对象是简单查询还是组合查询。
利用/\b /.test(queryString)去判断查询语句是否有空格
准确来说,是判断一个单词后是否有空格。 例如:“#id .class”,会匹配到#id后的空格,而对于“ .class”则不能匹配到。
当为简单查询时
查询规则只有一条。但是却分为:
查询id对象(规则为#+“idName”),
查询class对象(规则为.+“className”),
查询特定属性对象(规则为[attrName]),
查询特定属性值对象(规则为[arrtName=arrtValue]),
查询tag对象(排除以上规则,剩下的就是查询tag对象)。
因为规则匹配符不同,所以使用switch(str.charAt(0)),根据匹配规则字符串的第一个字符做判断。
####1.查询id对象。直接利用JS的id选择器。因为id具有唯一性,所以并不需要遍历dom树。####
case "#":
// 去除id前的'#'字符,获取id值
name = str.replace(/^#/,"");
return document.getElementById(name);
####2.查询class对象。####
因为class的不唯一性,所以我们要去遍历dom树,把所有符合规则的dom节点都找到,放进一个数组。这里遍历dom使用的方法是利用js的createNodeIterator()创建一个dom迭代工具遍历dom树。
document.createNodeIterator(root, whatToShow, filter)
接受的参数有三个:
root:
遍历树的根节点,即迭代器遍历的起点。
whatToShow:
迭代器遍历的节点类型,默认是遍历所有节点。可以设置为`NodeFilter.SHOW_ELEMENT`,表示只遍历element节点。
filter:
节点过滤规则,过滤条件?NodeFilter.FILTER_ACCEPT : NodeFilter.FILTER_REJECT;
然后把符合过滤规则的节点放进一个数组,再返回该数组
代码:case ".":
name = rules[i].replace(/^\./,"");
var Iterator = document.createNodeIterator(parentNodeList[c],NodeFilter.SHOW_ELEMENT,
function(node){
return new RegExp("^"+name+"$").test(node.className)?NodeFilter.FILTER_ACCEPT : NodeFilter.FILTER_REJECT;
},false);
var currentNode;
while(currentNode = Iterator.nextNode())
{
temp.push(currentNode);
}
break;
####3.查询特定属性对象。####
对于属性对象,分为只查找属性对象和查找特定属性值对象,用正则表达式检验查询字符串里是否有“=”,有“=”就在dom迭代器的filter里设置过滤规则为:
node.getAttribute(attr)==value
如果没有,则只需要判断是否含有该属性,过滤规则filter设置为:
node.hasAttribute(name)
代码:略
####4.tag对象。####
对于tag对象,由于是不是复数查询,只需要使用
document.getElementsByTagName(str);
就足够了
当为复杂查询时
当查询条件为复数条件时,先找出符合最外层查询规则的dom节点,放进parentNodeList数组,以该数组内的节点为遍历起点,搜寻符合第二条查询规则的所有dom节点,清空原parentNodeList数组,将符合第二条查询规则的所有dom节点放进parentNodeList数组,以该数组内的节点为遍历起点,搜寻符合第三条查询规则的所有dom节点...直到查询到符合所有规则的节点
例如:$("#id .class i")
规则一为"#":
先找出id为id的节点,将该节点放进parentNodeList:[div.id]
规则二为".":
以div.id为起点,搜索它的后代节点,后代节点中类名为class的将被放进parentNodeList:[div.class,li.class,span.class]
规则三为tag:
分别以div.class,li.class,span.class为起点,搜索它的后代节点,后代中tag名为i的节点放进parentNodeList[li.class i,span.class i]
后面没有规则了,那么目前的parentNodeList就是我们要寻找的节点。返回parentNodeList。完成查询。
注意事项:
由于id选择器的唯一性,当有$(".class #id")这查询条件时(它的确很无聊而且没意义,可是可能有人就愿意这么查)。
我们以所有的.class节点为起点去查询#id节点,那么每个#id节点就被重复查询了,到时候返回的parentNodeList可能就是[div.id,div.id,div.id](重复的数目是看.class的节点数)。因为重复了很多次,所以要进行一次去重处理。
由于代码太长,放在demo里面了
query代码和demo
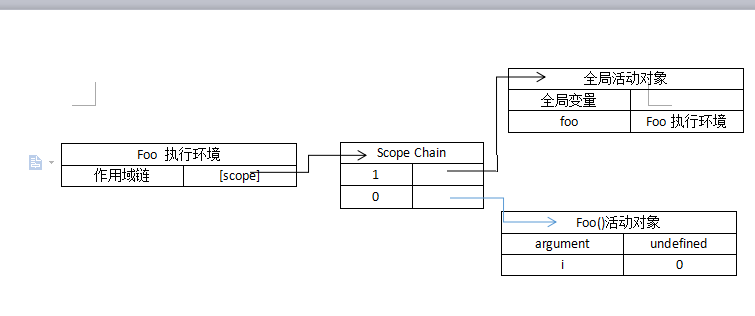
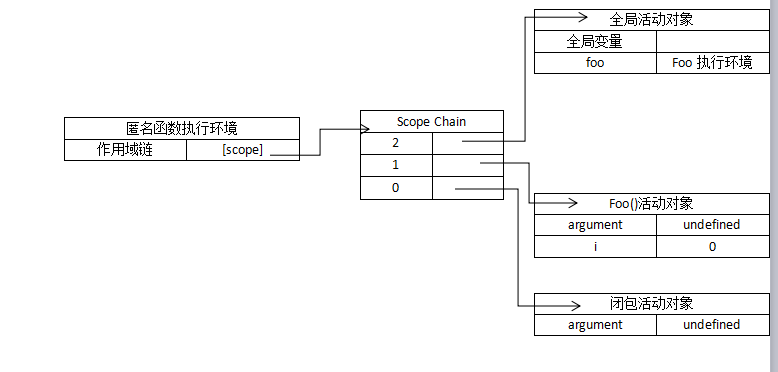 也正是因为闭包对外部函数的变量进行引用,所以无论外部函数是否存在,外部函数的活动对象都会保存在闭包的作用域链上!在闭包的生存期间,该变量并不会被垃圾回收例程回收。
也正是因为闭包对外部函数的变量进行引用,所以无论外部函数是否存在,外部函数的活动对象都会保存在闭包的作用域链上!在闭包的生存期间,该变量并不会被垃圾回收例程回收。